
クローラーからのアクセスを拒否するには .htaccess ファイルで設定できます。
この記事では、.htaccessでクローラーを拒否する2つの方法を紹介します。
.htaccessでクローラーを拒否する2つの方法
.htaccessでクローラーからのアクセスを拒否する方法は、2つあります。
- クローラーにステータスコード403(Forbidden)を返却することで、クローラーの巡回処理を禁止する
- クローラーにレスポンスヘッダX-Robots-Tagを出力することで、クローラーのインデックス処理を禁止する
ステータスコード403の返却は、Apacheがリクエスト処理を行っている段階で行うので、サーバー側の処理が軽くて済むのがメリットです。
Googleからのアクセスが多く、ネットワーク帯域やサーバーリソースに影響が出ているときには、効果があります。
一方、X-Robots-Tagヘッダを使うと、ネットワーク帯域やサーバーリソースは改善できませんが、既にGoogleにインデックスされてしまったコンテンツを削除することができます。
このように、2つの方法はよく似ていますが効果は違います。どちらをやりたいのかを正しく判断してみてください。
クローラーに403 Forbiddenを返す
「Google」「Bing」「Yahoo!」のクローラーからのアクセス時、403エラーを返却します。
.htaccessは次のように記述します。
BrowserMatch "Googlebot|Bingbot|Y!J-" crawler=true
RewriteEngine On
RewriteCond %{ENV:crawler} true
RewriteRule . - [F]
BrowserMatchディレクティブでUser-Agentからクローラーを判別し、環境変数crawlerをtrueに設定します。
あとは、RewriteCondとRewriteRuleでcrawlerがtrueの場合に限り、403エラーを返却しています。
なお、上記の.htaccessを記述すると、500 Internal Serverが発生することがあります。Apacheのエラーログに「Invalid command ‘RewriteEngine’」などが記録されている場合は、mod_rewriteを有効にしてください。
[Wed Mar 31 17:12:37.009516 2021] [core:alert] [pid 825:tid 139805429896960] [client 172.19.0.1:37046] /var/www/html/.htaccess: Invalid command 'RewriteEngine', perhaps misspelled or defined by a module not included in the server configurationX-Robots-Tag: noindexヘッダを出力する
HTTPレスポンスにX-Robots-Tagヘッダを出力するには、次の1行を.htaccessに記述します。
Header set X-Robots-Tag noindex
次のように、レスポンスヘッダに X-Robots-Tag が追加されました。
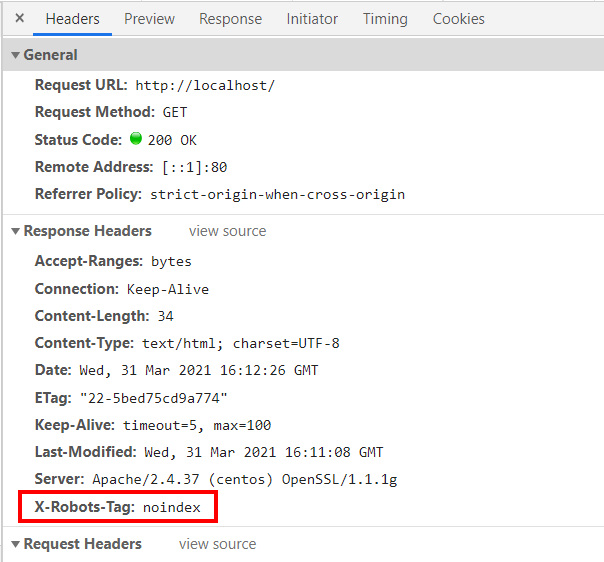
X-Robots-Tagヘッダは、<meta name=”robots”>と同じ効果を持ちます。
noindexを指定することで、クローラーは巡回したコンテンツをインデックス登録しないようになります。
まとめ
クローラーのブロックは、403エラーで大丈夫と考えてしまいがちですが、既にインデックス登録されたコンテンツはGoogle検索に表示されたままです。
Googleインデックスへの登録を拒否するのなら、noindexを指定するようにしましょう。

